Training on Your Data ≠ Leaking Your Data: What Fine-Tuning and Isolation Really Mean
Tired of nonsense pricing of DocuSign?
Start taking digital signatures with BoloSign and save money.
When companies first explore fine-tuning AI models with their own data, one question always comes up: does training on my private data mean I’m leaking it? It’s a fair worry. With everything we know about large language models occasionally regurgitating bits of their training data, it’s easy to assume that once you feed the model sensitive material—contracts, customer records, product notes—that information could somehow escape into the wild. But that’s not how fine-tuning actually works when it’s done right.
The truth is more nuanced. Training on your data and leaking your data are not the same thing. The first is a process of adaptation; the second is a failure of governance, privacy engineering, or both. To understand the difference, we have to unpack what fine-tuning really means, why isolation matters, and where the actual risks come from.
Understanding Fine-Tuning
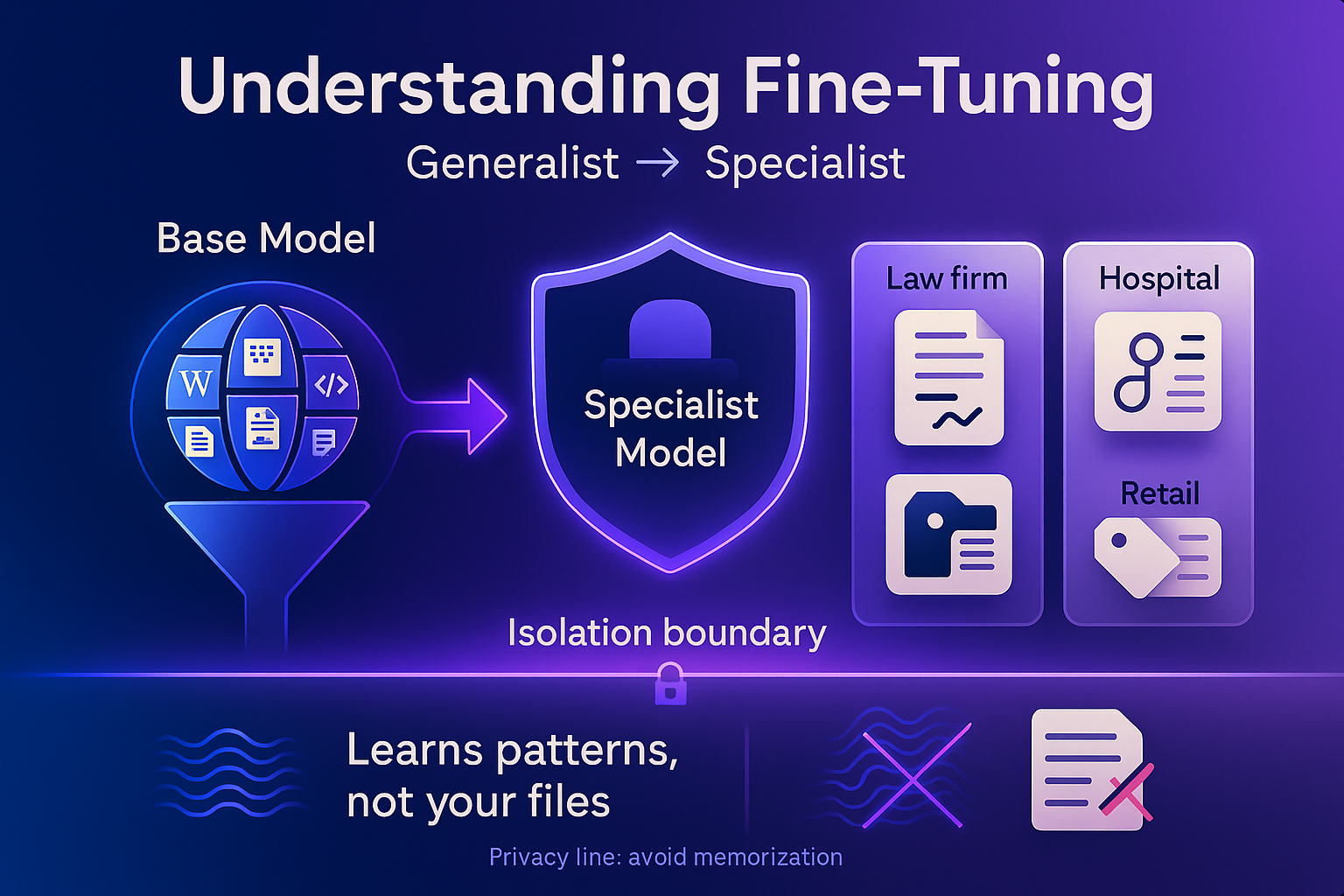
Fine-tuning is what turns a generalist model into a specialist. The base model has already learned a staggering amount from a massive general dataset—everything from Wikipedia to technical papers to open-source code. But it doesn’t know your company, your tone, your customers, or your workflows. That’s where fine-tuning comes in. You take this pre-trained model and train it a little more on your own examples so it adapts to your domain.
In technical terms, you’re adjusting the model’s internal parameters using your dataset, nudging it to prefer your patterns of language and logic. A law firm might fine-tune on contracts and case summaries. A hospital might use anonymized patient notes to help summarize clinical data. A retailer might fine-tune on product descriptions and support transcripts. The model becomes more contextually aware of your world.
The key thing to remember is that the model isn’t storing your files like a database. It’s not indexing your data in a way you can query directly. It’s learning from patterns—syntax, semantics, relationships—rather than saving literal copies of what you gave it. But while that’s true in principle, there’s still a line between learning from data and memorizing it, and that’s where the conversation about privacy begins.
Why People Fear Leaks

AI models have made headlines for occasionally parroting fragments of their training data. There are research papers where models reproduced names, phone numbers, or even verbatim passages from books they were trained on. It’s unsettling because it blurs the boundary between “learning” and “remembering.”
So when someone says “train the model on your internal data,” your brain immediately goes to the worst-case scenario: a model that starts spilling customer secrets if prompted the wrong way. And that fear isn’t baseless. If fine-tuning is handled carelessly, with no isolation or controls, you could indeed create a system that exposes information it shouldn’t.
Another reason for concern is the rise of what researchers call membership inference attacks. In these, an attacker tries to determine whether a specific record—say, an individual’s medical case—was part of a model’s training set. Even without seeing the data directly, these attacks can infer private participation. It’s one of the reasons regulators are now paying close attention to how organizations train and deploy AI systems.
But to assume that every fine-tuned model is inherently unsafe is like saying every lock is breakable, therefore no door is secure. The truth lies in how you handle isolation, access, and the fine-tuning process itself.
What “Isolation” Really Means
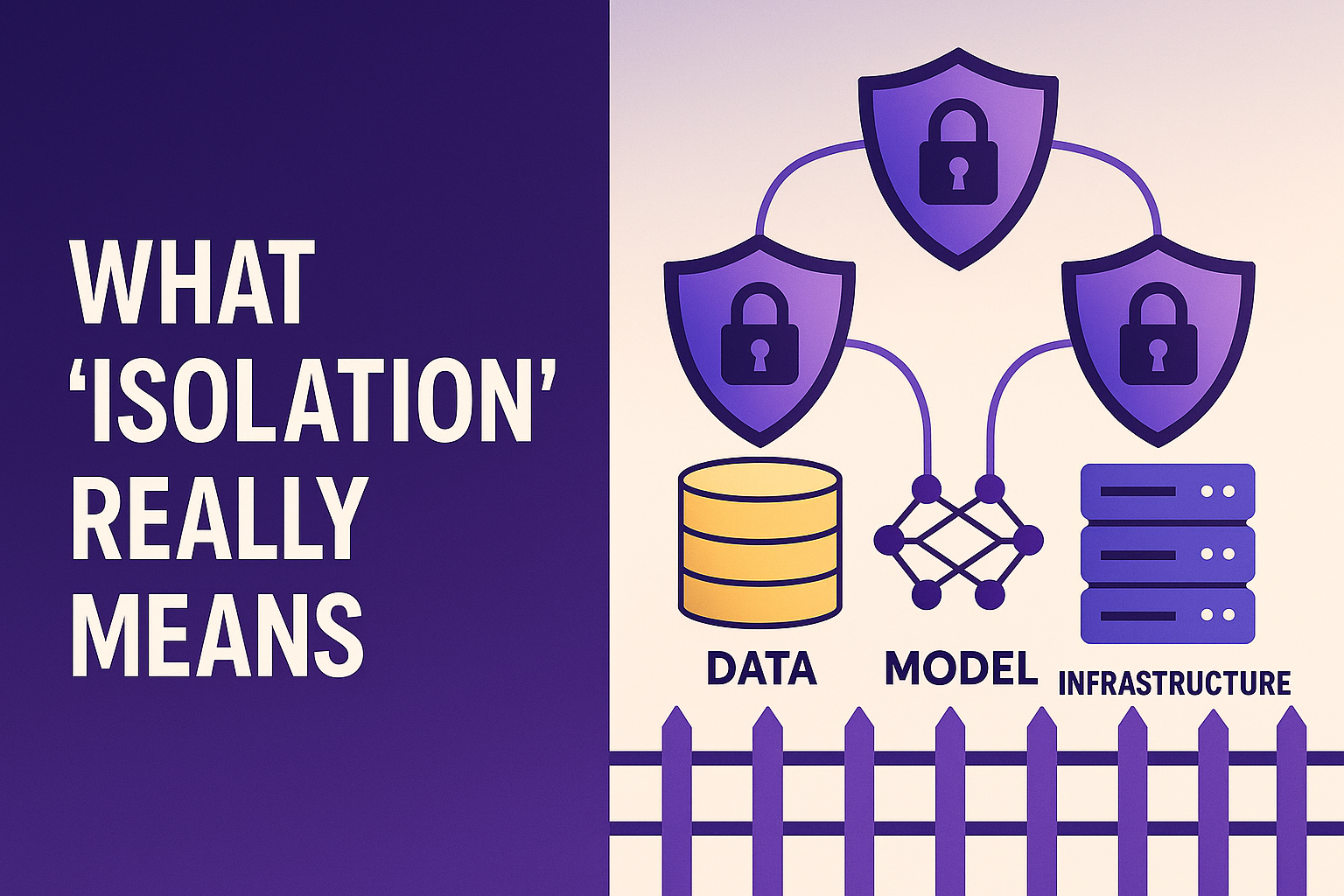
Isolation isn’t a marketing buzzword. It’s an engineering discipline. It means your data, model, and infrastructure are fenced off so nothing gets exposed unintentionally.
At the most basic level, you isolate your data. The dataset you use for fine-tuning should be stored securely—encrypted, access-controlled, and never mixed into any shared or public training pools. You don’t upload it to a random endpoint or third-party service that doesn’t guarantee privacy boundaries.
Then you isolate your model. Once fine-tuned, that model should live within your controlled environment. You decide who can query it, what they can ask, and what it can return. If you expose it publicly without restriction, you’re effectively inviting people to probe it for secrets. But if it sits behind proper authentication, API limits, and monitoring, the risk of data leakage drops dramatically.
There’s also environmental isolation. The infrastructure that performs fine-tuning—servers, storage, networks—must be hardened. That means encryption at rest and in transit, restricted network access, no unlogged data movement, and a clear separation between your compute resources and anyone else’s. In enterprise setups, this is why fine-tuning often happens inside virtual private clouds with auditable activity logs.
Isolation, in short, isn’t a single setting. It’s a combination of physical, digital, and procedural boundaries that make sure your model learns from your data without letting anyone else near it.
Why Training ≠ Leaking
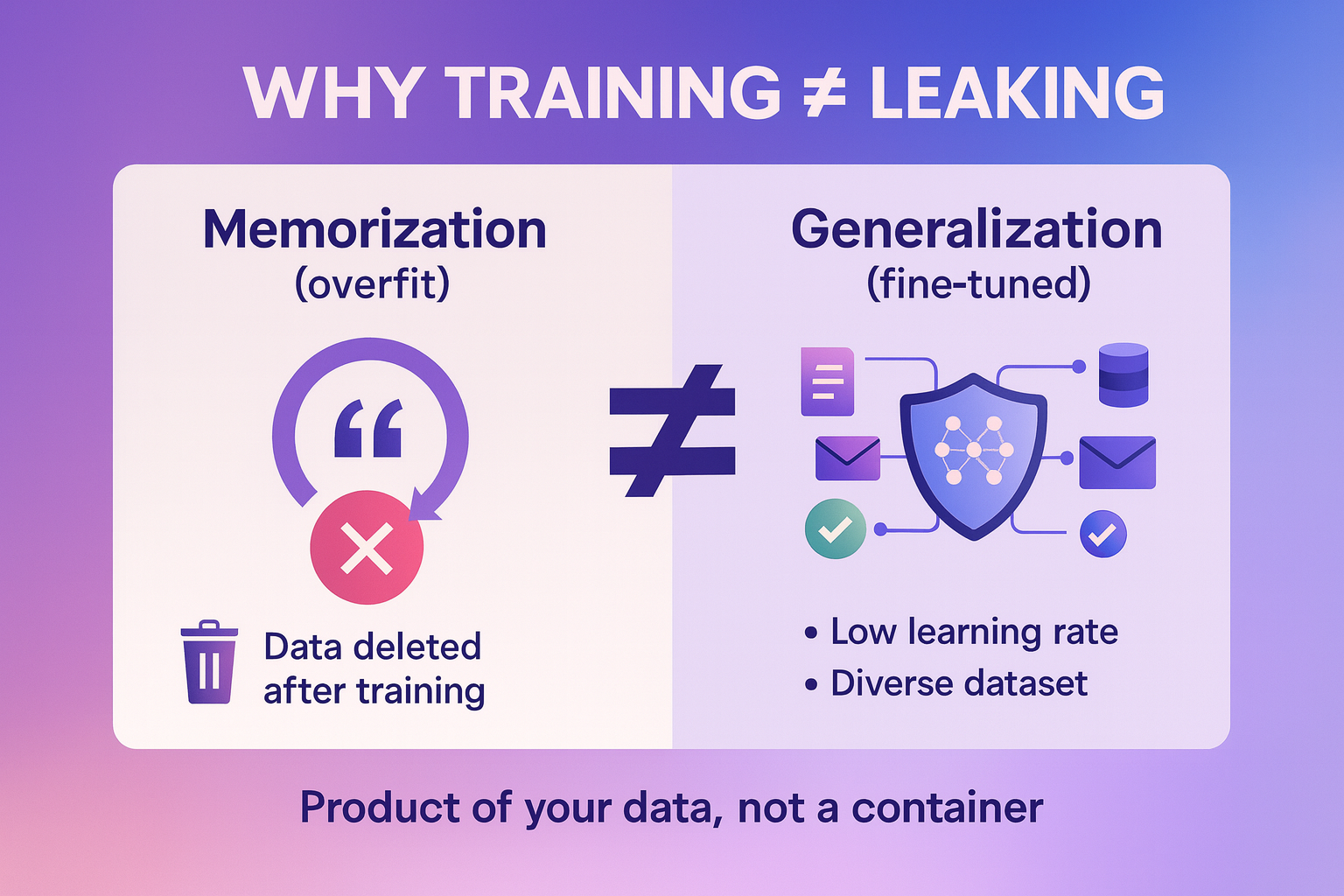
Now that we’ve defined isolation, it’s easier to see why training on your data does not automatically mean leaking it. When you fine-tune responsibly, the model isn’t memorizing and regurgitating sentences. It’s adjusting statistical weights that represent general relationships.
Imagine teaching someone your company’s communication style. You show them a bunch of emails so they learn how to write like you. If they understand the tone and structure, they can generate similar messages later without quoting the exact sentences you showed them. That’s essentially what good fine-tuning does: it teaches style, reasoning, and context—not raw recall.
A fine-tuned model is therefore a product of your data, not a container of it. The moment training ends, the data can even be deleted from the environment, and the model will still perform because it’s internalized patterns rather than examples.
The problem arises only when the model overfits—that is, it memorizes instead of generalizing. This can happen if your dataset is tiny, repetitive, or too specific. The model starts to latch onto particular phrases or numbers because it doesn’t have enough diversity to learn general rules. That’s why experienced teams use larger, more varied datasets and lower learning rates during fine-tuning: they teach the model to adapt gently, not obsessively.
Where Things Can Go Wrong

Despite the safeguards, leaks do happen. And almost every time, they’re caused by preventable mistakes rather than the concept of fine-tuning itself.
One major culprit is memorization. If you fine-tune on sensitive data without controlling for overfitting, the model may reproduce fragments of the input when probed cleverly. Researchers have shown examples where fine-tuned models revealed snippets of personally identifiable information from their training sets.
Another risk comes from weak access control. You can have a perfectly fine-tuned model, but if it’s deployed in a public demo where anyone can prompt it with arbitrary inputs, someone can extract unintended information through trial and error. The vulnerability isn’t in the training—it’s in the exposure.
Sometimes the risk isn’t even at the model level. Logs, checkpoints, or backups created during training can contain portions of the dataset. If those aren’t encrypted or deleted, they become easy targets. And when fine-tuning happens on shared or third-party infrastructure without contractual privacy guarantees, you’ve essentially invited strangers into your lab.
Finally, there’s the psychological trap of false security. Many teams assume that “private fine-tuning” equals “no risk.” They treat isolation as a checkbox rather than a practice. Without periodic audits, privacy testing, and red-team probing, you’ll never know if your supposedly private model is leaking under the surface.
Building a Privacy-Conscious Fine-Tuning Process
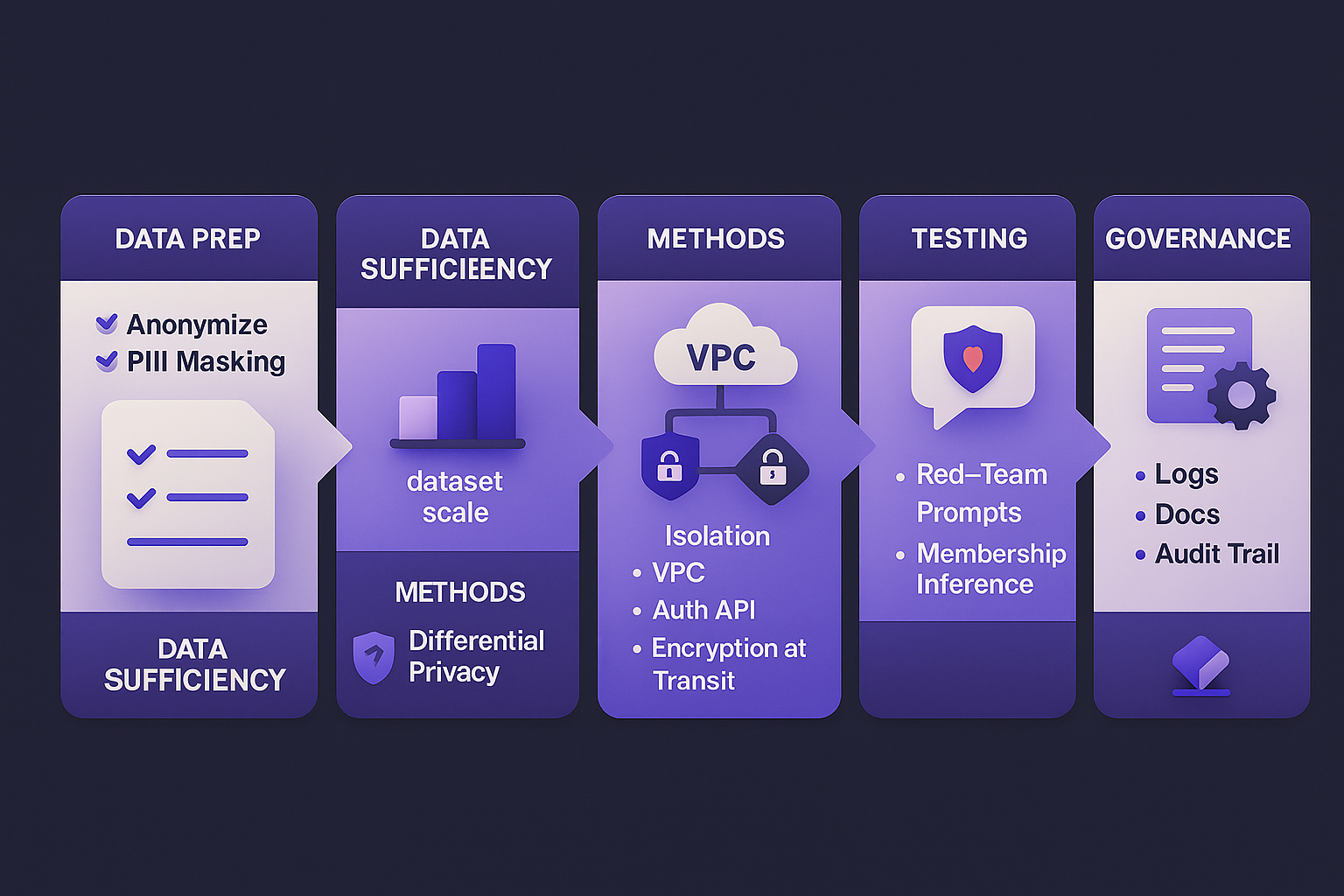
A safer process starts long before you press “train.” It begins with how you prepare the data. Anything sensitive that doesn’t add direct learning value should be removed or masked. Personally identifiable information should be anonymized or pseudonymized whenever possible. If your dataset contains client records, redact names, addresses, and phone numbers. Replace them with placeholders or representative patterns so the model learns structure, not identity.
Then comes data sufficiency. Using too little data increases the risk of memorization. Think of it like teaching from flashcards: if you only show a few, the student remembers the cards instead of the concept. The same principle applies here. Broader, more representative datasets produce safer models.
On the technical side, modern fine-tuning doesn’t always mean retraining the entire model. Many teams now utilize methods such as adapter tuning or low-rank adaptation (LoRA). These techniques train smaller layers on top of the base model, rather than rewriting every weight. They’re cheaper, faster, and often less prone to overfitting, which means less risk of data recall.
You can also fine-tune with differential privacy. This approach adds mathematical noise during training so that the model can’t over-rely on any single data point. Google Research and others have shown that it’s possible to fine-tune large models with differential privacy while maintaining strong performance. It’s one of the most promising directions for balancing personalization and confidentiality.
Once the model is trained, the security focus shifts to the environment. You want your fine-tuned model living in an isolated network, preferably behind an authenticated API. Data at rest should be encrypted, data in transit should use secure protocols, and all access should be logged. If you’re training or hosting in the cloud, make sure you understand the provider’s guarantees: who owns the model, who can access the fine-tuning data, and what happens to that data after training. Platforms like Amazon Bedrock or Azure OpenAI provide these isolation options explicitly because enterprise users demand them.
Before deployment, test the leakage model. This isn’t theoretical—teams literally run “red-team” prompts to see if the model will reveal sensitive information. They might ask it to reproduce names, numbers, or specific phrases from the training data. If it ever does, the fine-tuning parameters or dataset need rework.
Testing should also include what researchers call “membership inference.” That’s when you check whether the model’s behavior changes noticeably for records that were part of the training set versus those that weren’t. If an attacker can tell the difference, you have a privacy issue.
And finally, governance matters as much as technology. Keep documentation of what data you used, where it came from, and how it was handled. Record who had access and when. Retain evidence of privacy tests. These things aren’t bureaucratic—they’re your proof of due diligence, both for regulators and for customers.
What Isolation Achieves in Practice
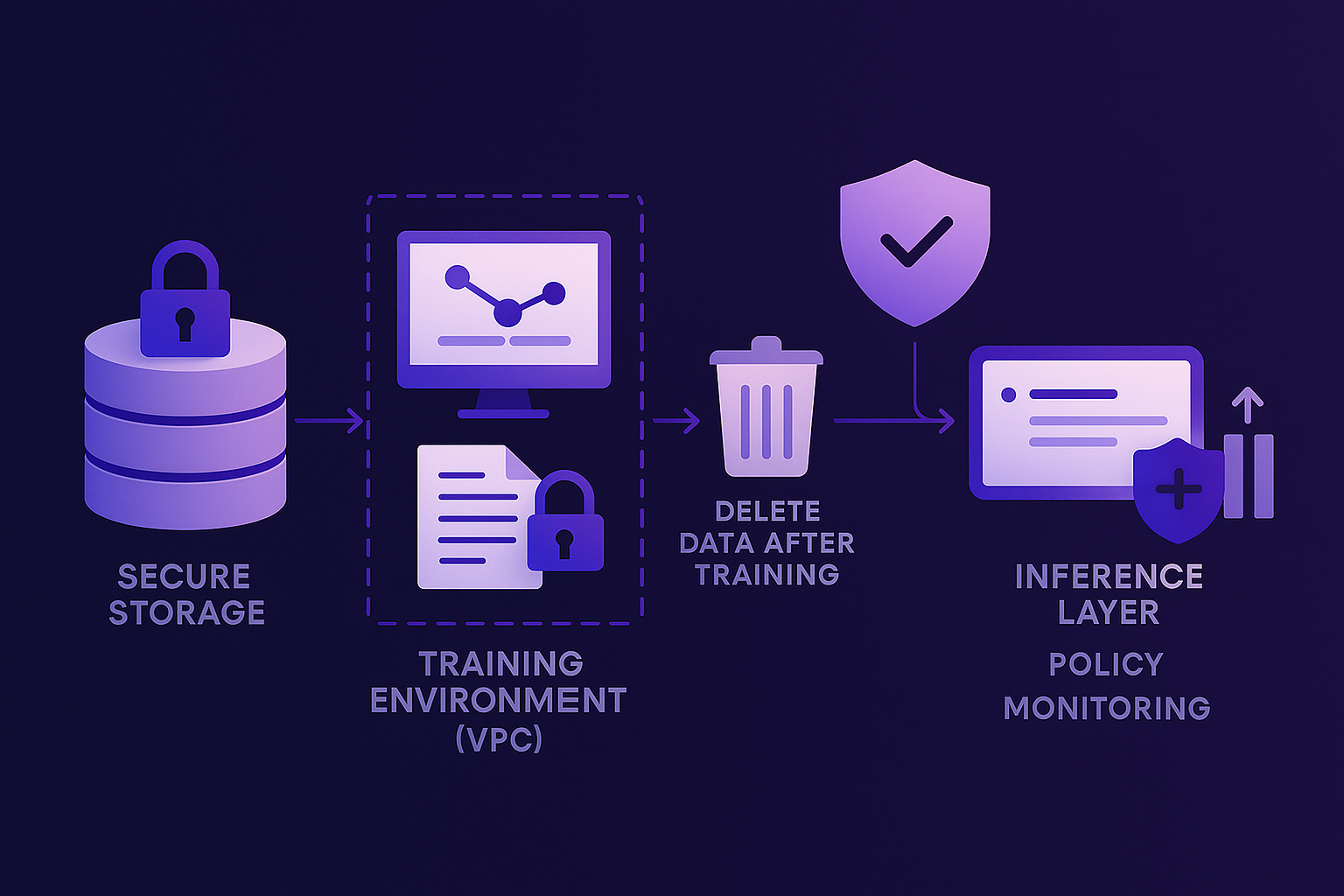
When you combine proper fine-tuning techniques with real isolation, something powerful happens. You get the benefits of specialization without the risks of exposure.
Your private data lives in a secure storage layer, accessible only during training. The training process itself happens inside a controlled environment where every access is logged and encrypted. After training, the model weights are saved, but the raw data is deleted or archived securely. The model that emerges is informed by your data but not dependent on it.
When users interact with the model, they’re not querying your dataset; they’re querying a system that has learned from your dataset. The requests and responses are handled by an inference layer you control, with rules that prevent unrestricted prompts. If someone tries to extract secrets or abuse the model, you can detect it, log it, and shut it down.
This is the essence of safe AI personalization. You’re not pouring private data into a public black box—you’re building a private instance of intelligence, shaped by your data but fenced by your rules. And when you operate this way, “training on your data” becomes an advantage, not a liability.
A Sensible Workflow
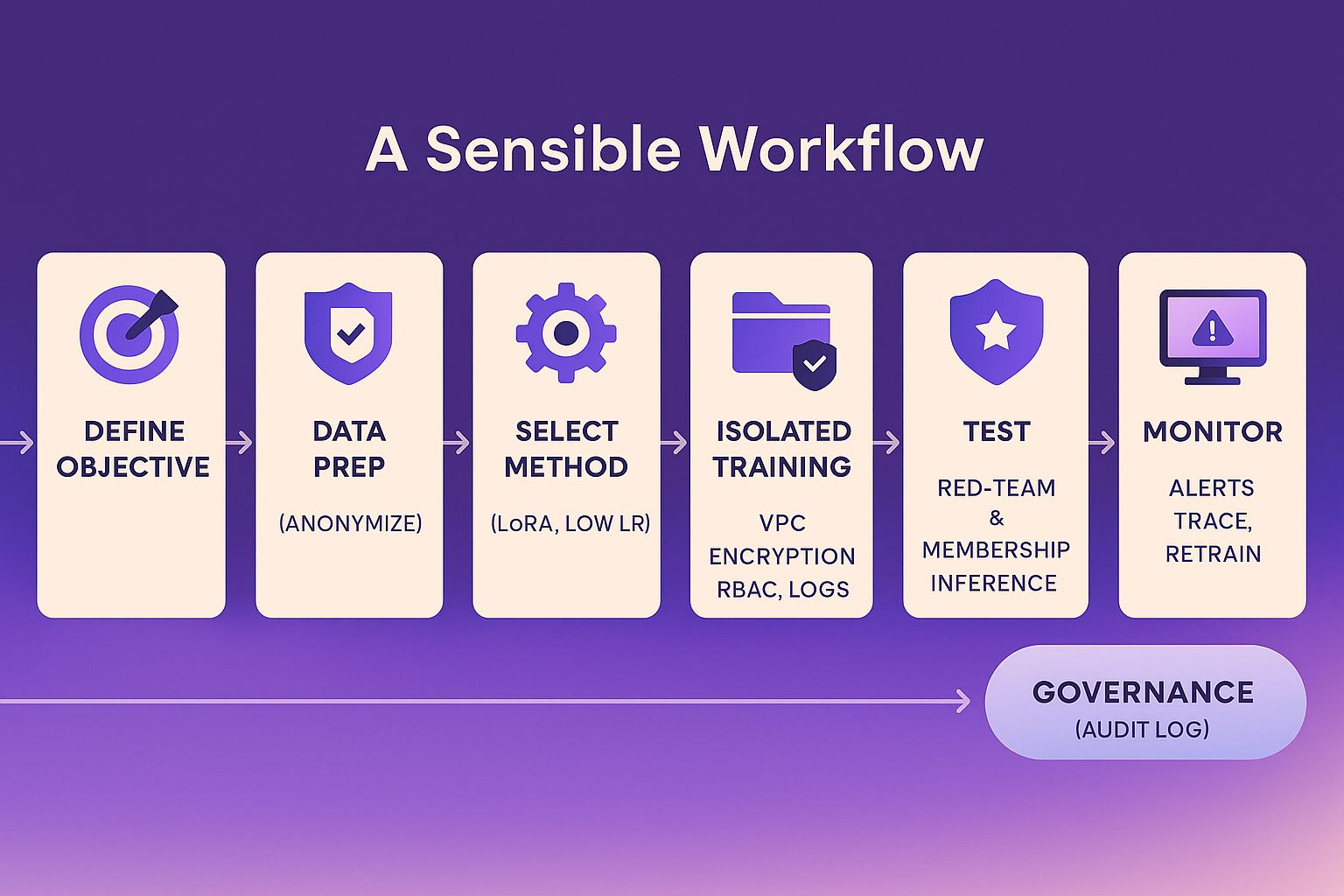
If we translate all of this into an ideal workflow, it would look something like this in narrative form.
You start by defining why you want to fine-tune at all. Maybe your customer support model needs to answer with your company’s tone, or your document summarizer needs to understand your contract templates. You gather the relevant examples, review them for sensitivity, and clean them up. Anything that identifies people or companies gets anonymized.
Next, you select the fine-tuning method. Maybe you use a LoRA adapter because it’s efficient and easier to manage. You set your learning rate low enough to avoid overwriting the model’s base knowledge. You run the training inside your company’s private cloud or a trusted provider’s isolated environment. Access is limited, data is encrypted, and everything is logged.
Once the model finishes training, you archive the data and wipe it from the training environment. Then you start testing. You probe the model with prompts designed to tease out any memorized content. You check for names, phone numbers, or specific lines from your training set. You compare outputs against reference records to confirm that no private data is echoed.
Only after passing those tests do you deploy it to production. You wrap the model behind an authenticated API with role-based access control. You monitor queries to detect anomalies. If the model starts returning something unexpected, you can trace and retrain. And you maintain a governance trail documenting what was trained, on what data, and under which conditions.
At that point, you have something powerful and safe: an AI that’s personalized to your context without compromising your privacy. You can use it internally with confidence, or even externally with appropriate guardrails. The phrase “training on your data” no longer sounds dangerous—it sounds strategic.
The Broader Meaning of “Safe Customization”
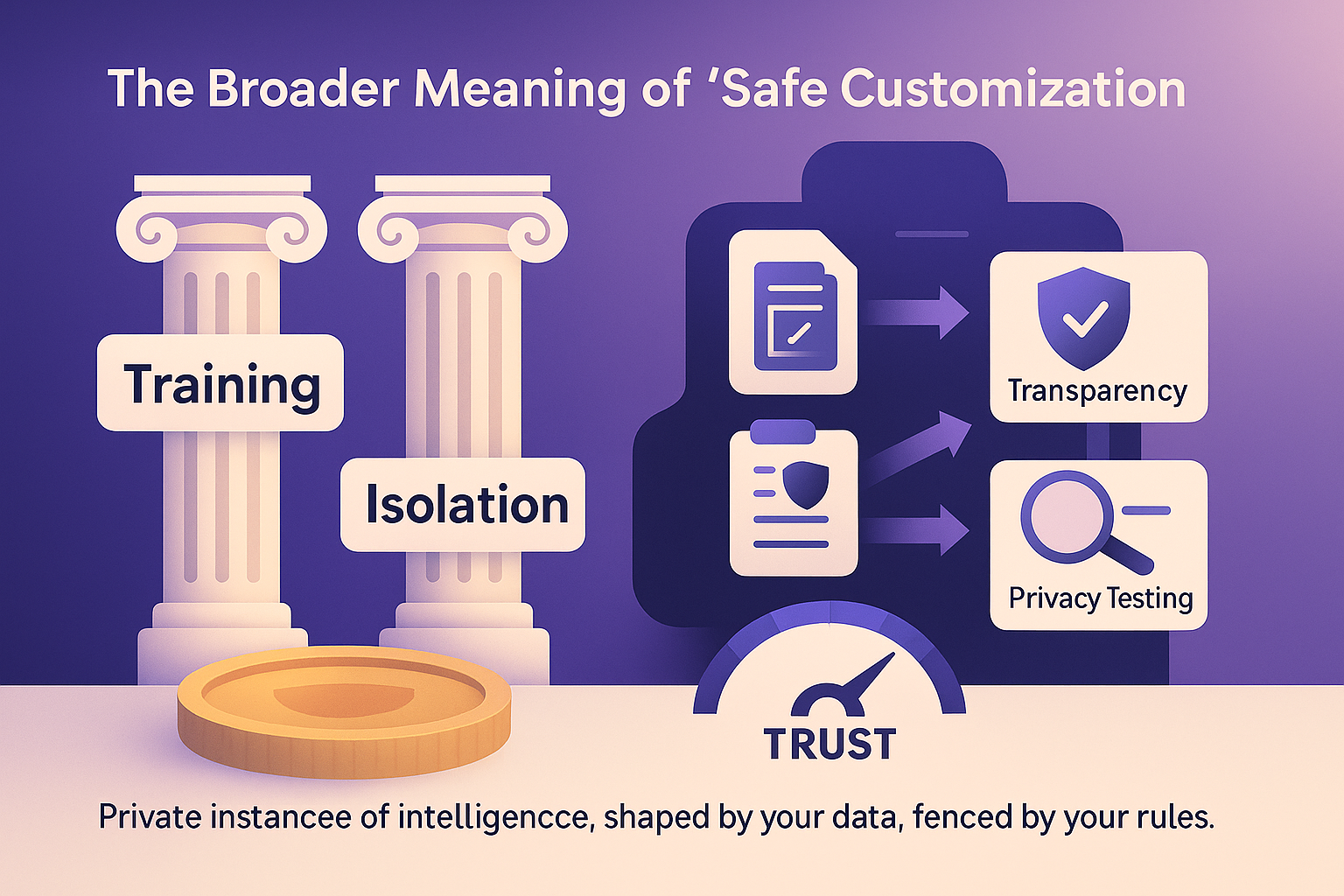
There’s a bigger philosophical takeaway here. Fine-tuning represents a shift in how organizations think about AI. Instead of consuming general-purpose intelligence, they’re shaping their own. But with that power comes responsibility: if you want your model to understand your business, you have to feed it information your business cares about. And that information is often sensitive.
So safety can’t be an afterthought. It’s not something to layer on after the fact with compliance language or access policies. It has to be part of the system’s DNA. Training and isolation are two sides of the same coin. One builds capability; the other builds trust.
When people conflate training with leaking, they’re really expressing a lack of trust in how AI systems are handled. The best way to rebuild that trust is transparency—showing that you have processes for isolation, governance, and privacy testing. Once stakeholders understand that fine-tuning doesn’t mean handing data to an uncontrolled black box, their perception changes. They see AI not as a security risk but as a controlled, internal intelligence engine.
Final Reflection
Training on your data and leaking your data are fundamentally different acts. One is about teaching a model to serve you better; the other is about failing to secure what you’ve taught it. The boundary between them is defined by isolation, discipline, and design.
If you approach fine-tuning with rigor—clean datasets, secure environments, differential privacy, strong access control, and ongoing testing—you can unlock enormous value without crossing that boundary. Your model becomes a mirror of your organization’s intelligence, not a portal to its secrets.
In an era where data privacy defines reputation, this distinction matters more than ever. Companies that master safe fine-tuning will own their intelligence pipelines. Those who ignore isolation will find their trust eroded quickly.
So the next time someone says “train the AI on your data,” don’t flinch. Ask how they isolate, how they govern, and how they test. The answers to those questions—not the training itself—determine whether your data remains yours.
That’s what “Training on Your Data ≠ Leaking Your Data” really means.

Paresh Deshmukh
Co-Founder, BoloForms
24 Oct, 2025
Take a Look at Our Featured Articles
These articles will guide you on how to simplify office work, boost your efficiency, and concentrate on expanding your business.